
|
Christ is my all
|

San Antonio, TX


San Antonio, TX

San Antonio, TX

That's life, isn't it? Actually, that's life when you're young and just starting out. I've been growing plant for around 40 years, and there have been plenty of mass extinction events along the way, but you learn, you try again, and eventually you amass a decent garden, whether its houseplants, flowers, or vegetables -or all three! The real secret to convincing people you have a green thumb is to quickly get rid of the failures. Never speak of them. That way, all your friends and neighbors will see are your successes. This comic is from Sarah Andersen at Sarah's Scribbles.
San Antonio, TX
Here’s a real gem that a reader sent me. Tomtoc is a maker of laptop bags and sleeves. Visit their homepage and, of course, you’ll get a dickover asking you to join their mailing list “for exclusive updates and get a chance to win a free tech pouch every month.” But here’s the gem. If you do subscribe, and you decide later to unsubscribe, you get this:
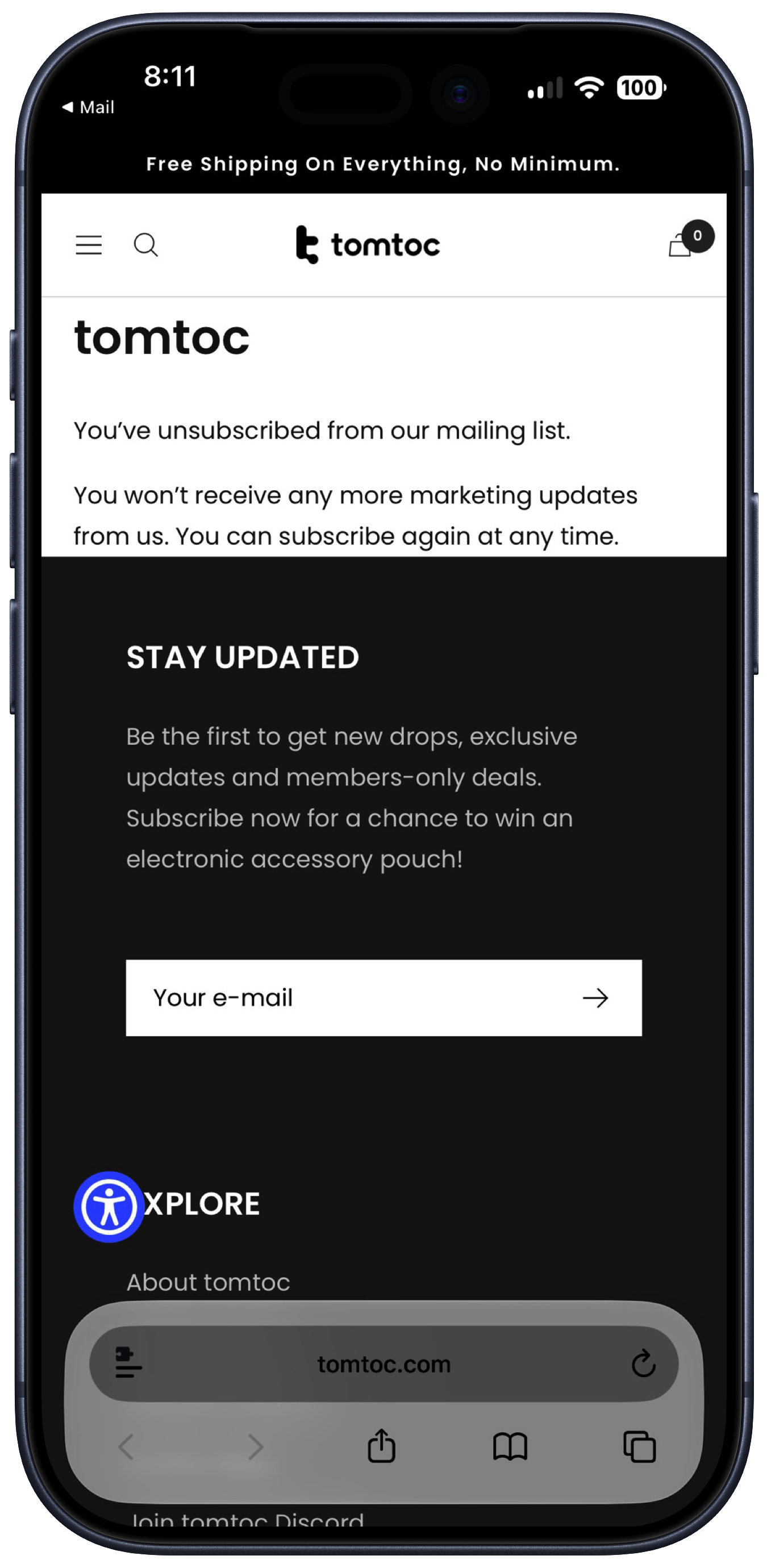
San Antonio, TX

This one gives me the creeps.
San Antonio, TX
Next Page of Stories